
1
2
Intel IOMMU Introduction https://kernelgo.org/intel_iommu.html
https://blog.csdn.net/21cnbao/article/details/106293976
对于Intel的硬件辅助虚拟化方案而言核心的两大技术分别是VT-x和VT-d。 其中VT-x中主要引入了non-root模式(VMCS)以及EPT页表等技术,主要关注于vCPU的虚拟化和内存虚拟化。 而VT-d的引入则是重点关注设备直通(passthrough)方面(即IO虚拟化)。
VT-x中在non-root模式下,MMU直接使用EPT page table来完成GPA->HVA->HPA的两级翻译, VT-d中在non-root模式下,则由IOMMU来使用Context Table和IOMMU page table完成设备DMA请求过程中的HPA->HVA->GPA的翻译. 二者极为相似,唯一的不同之处在于CPU访问内存(直通设备IO Memory)是通过MMU查找EPT页表完成地址翻译, 而直通设备访问内存的请求则是通过IOMMU查找IOMMU页表来完成地址翻译的。本文重点来探索一下Intel IOMMU的工作机制。
非根模式是Guest CPU的执行环境,根模式是Host CPU的执行环境
IOMMU - vt-d intel virtualization Technology for Directed I/O
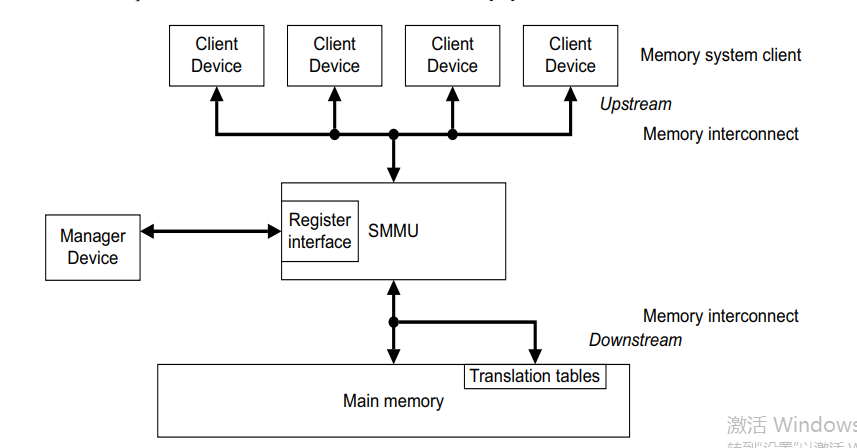
以Intel的IOMMU来分析:
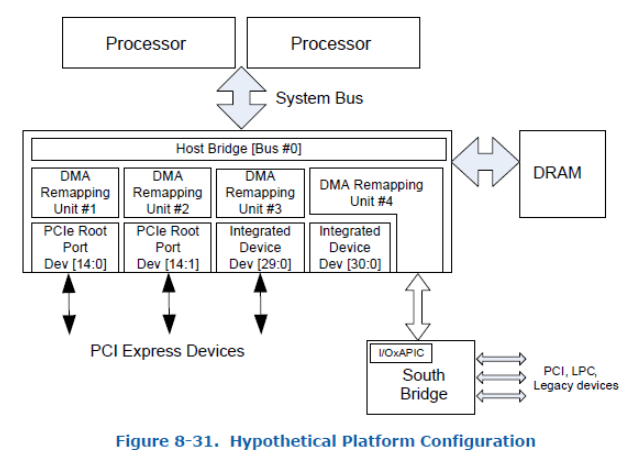
一、虚拟地址
1、虚拟地址空间:iova domain
iommu probe时,初始化iova domain
1>初始化保留区域
dmar_init_reserved_ranges 初始化reserved_iova_list 初始化保留的区域。
1
2
3
4
5
detect_intel_iommu
|-> pci_iommu_init
|->intel_iommu_init:5148
|->dmar_init_reserved_ranges
|->init_iova_domain &reserved_iova_list
- reserved_iova_list reserve部分,DMA不可用的地址
下面两种range是需要保留的:
1 IOAPIC 0xfee00000~0xfeefffff APIC的寄存器地址:0xfee00000
2 所有PCI设备的MMIO空间 IORESOURCE_MEM
2> 按iommu_group做iova domain申请
domain_alloc
1
2
3
4
5
6
7
intel_iommu_init: 5187
|->probe_acpi_namespace_devices
|->iommu_probe_device
|->iommu_alloc_default_domain
|->__iommu_domain_alloc
|-> intel_iommu_domain_alloc / domain_alloc
|->intel_init_iova_domain if IOMMU_DOMAIN_DMA
2、虚拟地址分配:
1> alloc_iova
1
2
3
4
5
6
//dma_alloc dma_map
intel_dma_ops.map_page
|->intel_alloc_iova //if dev->dmamask > 32, 先32bit以下,申请不到使用dev->dmamask
|->alloc_iova_fast
|->__iova_rcache_get //从rcache申请,fast路径
->alloc_iova if rcache not get //从iova_domian->rbroot中获取空闲
在rbtree中查找合适的位置,赋值给IOVA,并将其插入到rbtree中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
static int __alloc_and_insert_iova_range(struct iova_domain *iovad,
unsigned long size, unsigned long limit_pfn,
struct iova *new, bool size_aligned)
{
...
/* Walk the tree backwards */
spin_lock_irqsave(&iovad->iova_rbtree_lock, flags);
...
curr = __get_cached_rbnode(iovad, limit_pfn);
curr_iova = rb_entry(curr, struct iova, node);
do {
limit_pfn = min(limit_pfn, curr_iova->pfn_lo);
new_pfn = (limit_pfn - size) & align_mask;
prev = curr;
curr = rb_prev(curr);
curr_iova = rb_entry(curr, struct iova, node);
} while (curr && new_pfn <= curr_iova->pfn_hi);
...
/* pfn_lo will point to size aligned address if size_aligned is set */
new->pfn_lo = new_pfn;
new->pfn_hi = new->pfn_lo + size - 1;
/* If we have 'prev', it's a valid place to start the insertion. */
iova_insert_rbtree(&iovad->rbroot, new, prev);
__cached_rbnode_insert_update(iovad, new);
...
}
alloc_iova是最简单的分配机制,没有guard区域。申请的iova地址就是连续的。
验证:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
static __init int test_module_init(void)
{
struct iova_domain *test_iovad;
struct iova *iova1, *iova2;
test_iovad = kmalloc(sizeof(struct iova_domain), GFP_KERNEL);
init_iova_domain(test_iovad, 1UL << 12, 0);
iova1 = alloc_iova(test_iovad, 1UL << 12, 1UL << 32, 1UL << 12);
iova2 = alloc_iova(test_iovad, 1UL << 12, 1UL << 32, 1UL << 12);
printk("iova1 %lx %lx\n", iova1->pfn_lo, iova1->pfn_hi);
printk("iova2 %lx %lx\n", iova2->pfn_lo, iova2->pfn_hi);
__free_iova(test_iovad, iova1);
__free_iova(test_iovad, iova2);
kfree(test_iovad);
return 0;
}
1
2
[ 110.267837] iova1 fffff000 ffffffff
[ 110.267838] iova2 ffffe000 ffffefff
2> free_iova
1
2
3
4
//dma_unmap
free_iova_fast
|->iova_rcache_insert //can insert rcache? if true, insert and return;
-> free_iova if can not insert rcache //从iova_domian->rbroot 删除对应项
3> split_and_remove_iova
有功能实现,但无调用关系,也未导出。
总结:
1、虚拟地址空间
-
虚拟地址有不可用的空间,需要被预留
-
2、按照iommu_group分别独立虚拟地址空间
2、虚拟地址分配
- rcache层做快速分配128K以下
- rbtree记录已申请部分,进行分配
一、疑问
1、硬件无关的内存管理部分但有与具体功能(或者特殊限制等等因素)导致不同硬件存在差异怎么处理?
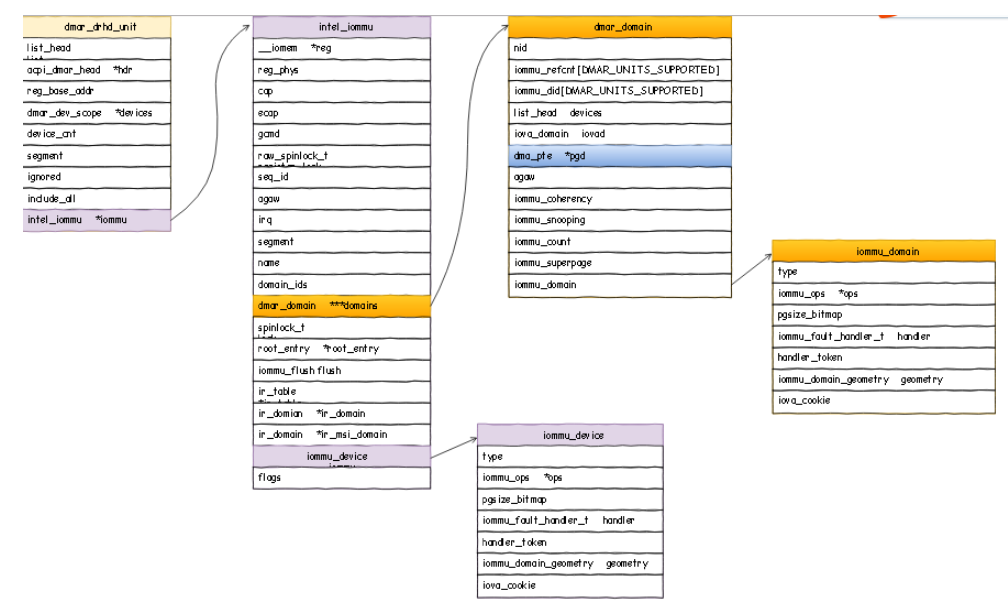
- struct inte_iommu:iommu硬件在驱动层所对应的概念
- struct iommu_group: 一个group下面可以对应多个或者一个硬件设备,使用相同的streamid
- struct dmar_domain: dmar_domain里面存储的是iova->hpa的转换页表,一个dmar_domain可以为多个或者一个设备服务。
- struct iommu_domain: 一个iommu_domain里面可以有多个iommu_group,然后每个iommu_group通过iommu_domain最终找到dmar_domain进行转换。
二、逻辑映射iova_to_phys
对于IOMMU的iova_to_phys是必要,驱动需要获取phys做访问。
linux的实现都是遍历页表获取对应phys。
1、SMMU
arm_lpae_iova_to_phys
1
2
3
4
struct iommu_ops arm_smmu_ops.iova_to_phys
+-> arm_smmu_iova_to_phys
+->struct io_pgtable_ops.iova_to_phys //arm_lpae_alloc_pgtable函数installed
+->arm_lpae_iova_to_phys //在内存上做多级页表遍历,获取最后的phys
2、intel IOMMU:
1
2
3
struct iommu_ops intel_iommu_ops.iova_to_phys
+->intel_iommu_iova_to_phys
+->pfn_to_dma_pte //走页表,如果没有映射,分配页添加映射
三、SMMU与Intel IOMMU的页表管理
1、SMMU的页表:
reference: SMMUv3_architecture_specification_IHI0070B
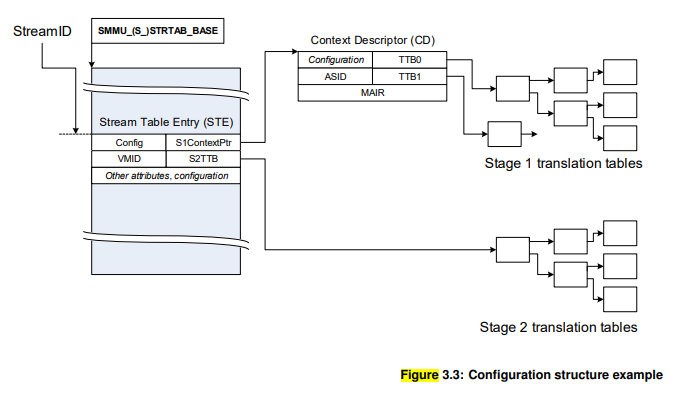
1
2
3
4
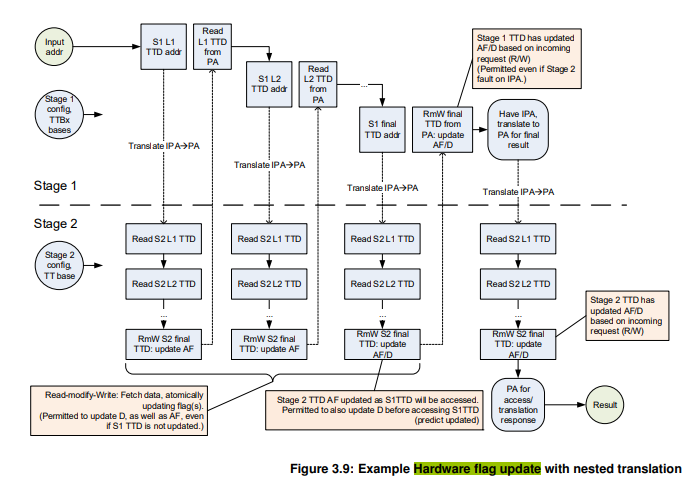
3.13.5 HTTU with two stages of translation
When two stages of translation exist, multiple TTDs determine the translation, that is the stage 1 TTD, the stage 2
TTDs mapping all steps of the stage 1 walk, and finally the stage 2 TTD mapping the IPA output of stage 1.
Therefore one access might result in several TTD updates
![]()
1
Stage1和Stage2同时支持AArch32(LPAE: Large Page Address Extension)
显而易见:
1>SMMU/IOMMU的页表存在主存上
2>SMMU的页表级数为4级
3>支持page size: IDR5_GRAN4K<4K 2M 1G>; IDR5_GRAN16K<16K 32M>; IDR5_GRAN64K<64k 512M>
Smmu的页表walk函数:arm_lpae_iova_to_phys
IO pagetable TLB flush函数:io_pgtable_tlb_flush_all、io_pgtable_tlb_add_flush、io_pgtable_tlb_sync
1、map 页表
SMMU的嵌套翻译:stage1 + stage2.
1
2
3
TT - Translation table, synonymous with Page Table, as used by ARM architecture
TTD - Translation table descriptor, synonymous with Page Table Entry, as used by the ARM architecture
LPAE - Large Physical Address Extension
1
2
3
4
5
//iommu_dma_ops arm_smmu_ops
io_pgtable_init_table
->io_pgtable_arm_64_lpae_s1_init_fns.alloc //arm_64_lpae_alloc_pgtable_s1 钩子1 硬件
->__arm_lpae_alloc_pages
//cfg->arm_lpae_s1_cfg.ttbr[0] = virt_to_phys(data->pgd)
1
2
3
//iommu_domain->ops->map
arm_lpae_alloc_pgtable
->data->iop.ops
1
2
3
4
5
dma_map_single
-> iommu_dma_ops.map_page// __iommu_dma_map 钩子2 DMA框架
->iommu_map
->iommu_domain->ops->map //arm_smmu_map 钩子3 IMMU框架
->arm_lpae_map
2、TLB flush函数
arm64 SMMU: arm_smmu_flush_ops
通过cmdQ发送TLBI命令,是对应的TLB无效化。
可参考SMMU spec 4.4章节
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
//io_pgtable_tlb_add_flush
static void arm_smmu_tlb_inv_range_nosync(unsigned long iova, size_t size,
size_t granule, bool leaf, void *cookie) {
if (smmu_domain->stage == ARM_SMMU_DOMAIN_S1) {
cmd.opcode = smmu->features & ARM_SMMU_FEAT_E2H ?
CMDQ_OP_TLBI_EL2_VA : CMDQ_OP_TLBI_NH_VA;
cmd.tlbi.asid = smmu_domain->s1_cfg.cd0->tag;
} else {
cmd.opcode = CMDQ_OP_TLBI_S2_IPA;
cmd.tlbi.vmid = smmu_domain->s2_cfg.vmid;
}
do {
arm_smmu_cmdq_issue_cmd(smmu, &cmd); //cmd S1: TLBI命令
cmd.tlbi.addr += granule;
} while (size -= granule);
}
2、intel IOMMU:
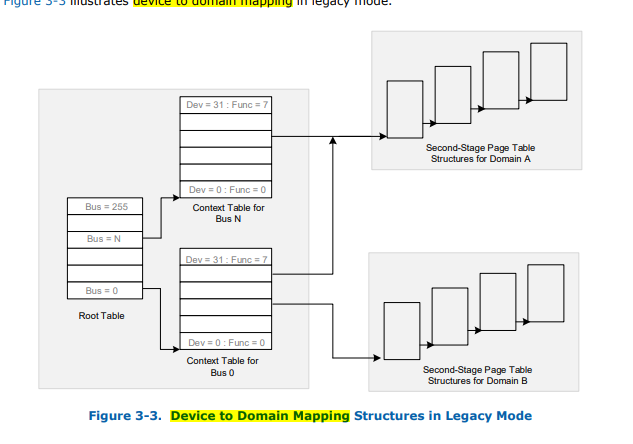

参考vt-directed-io-spec.pdf的第3.5章节: Hierarchical Translation Structures
IOMMU:
1> 支持4K 2M 1G的page size。
1、map页表
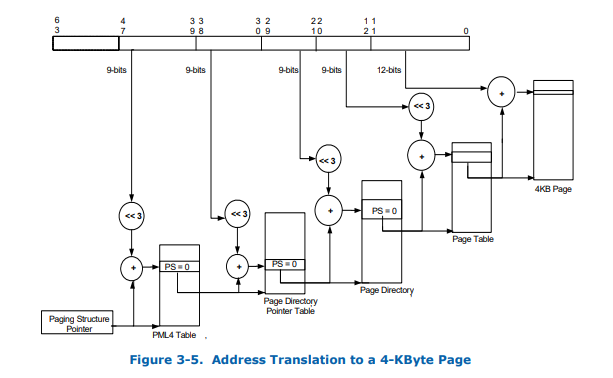
仅贴上4K,其他查看对应章节。4K table<9 9 9 9 12>
1
2
3
intel_iommu_ops.map
->intel_iommu_map
->domain_mapping
2、flush tlb
-
ASID-based IOTLB Invalidate Descriptor <DID + PASID + [start ] + [end]>
-
Device-TLB Invalidate Descriptor <Source-ID (SID) + [PASOID] + [start] + [end]>
Source-ID (SID): The SID field indicates the source-id of the endpoint device whose Device-TLB needs to be invalidated. -
GLOBAL FLUSH < DID>
IOMMU刷新tlb:__iommu_flush_iotlb or dmar_enable_qi
1
2
3
4
5
6
7
8
9
10
11
12
13
//__iommu_flush_iotlb
case DMA_TLB_GLOBAL_FLUSH:
/* global flush doesn't need set IVA_REG */
val = DMA_TLB_GLOBAL_FLUSH|DMA_TLB_IVT;
break;
case DMA_TLB_DSI_FLUSH:
val = DMA_TLB_DSI_FLUSH|DMA_TLB_IVT|DMA_TLB_DID(did);
break;
case DMA_TLB_PSI_FLUSH:
val = DMA_TLB_PSI_FLUSH|DMA_TLB_IVT|DMA_TLB_DID(did);
/* IH bit is passed in as part of address */
val_iva = size_order | addr;
break;
dmar_enable_qi支持按照地址和order来flush。
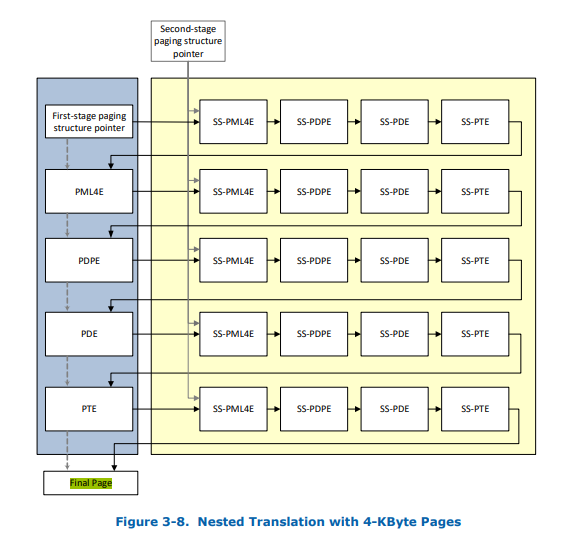
嵌套翻译:stage 1和stage 2同时使用的嵌套翻译。
3、amd iommu
1
2
3
1 domain->id是怎么用的,为什么能在iotlb flush的时候用上。然后搞清楚kpi中要不要给pmap_create增加参数
2 pmap_create在创建pmap时,应该增加一个自定义的参数,还是以gm_dev_create时增加的dev性质作为参考,不需要增加自定义的参数,即:以gm_dev_cap_t传入,还是架构上需要pmap_create时传入动态的自定义参数
3 增加一个遗留问题,iommu的iotlb coalesced invl的技术需要探索分iommu address space来invl
1
2
protection_domain_init
PDE: page directory
1
2
3
4
5
6
7
iommu_bus_notifier
->iommu_probe_device
bus_set_iommu
->iommu_bus_init
->bus_iommu_probe
->probe_iommu_group
1
2
3
4
5
6
//IOMMU_ENABLED ->amd_iommu_init_pci
1 -> iommu_group_alloc_default_domain
->__iommu_domain_alloc
2 -> __iommu_attach_device
-> set_dte_entry
->amd_iommu_dev_table<变量>
1
2
//IOMMU_ACPI_FINISHED
-> iommu_set_device_table
1
2
3
4
5
6
7
8
9
IOMMU_ACPI_FINISHED
->IOMMU_ENABLED
case IOMMU_ACPI_FINISHED:
early_enable_iommus();
x86_platform.iommu_shutdown = disable_iommus;
init_state = IOMMU_ENABLED;
break;
case IOMMU_ENABLED:
1
需要入参struct device + iommu_domain?
1
dev_iommu_priv_set
1
2
3
probe_device
->| iommu_init_device
->| devid = get_device_id() 总线 + 设备功能号
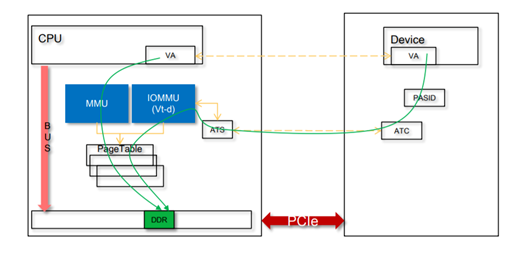
四、 ATS
1、ATS机制想要解决的问题
| | 对于IO设备往CPU的数据流,其IOMMU/SMMU/VT-d的查表性能在整个IO性能中显得极为关键,查表性能的好坏至今影响IO性能的好坏; |
| | 能够分担主机(CPU)侧的查表压力,特别是大带宽、大拓扑下的IO数据流,CPU侧的IOMMU/SMMU/VT-d的查表将会成为性能瓶颈,而ATS机制正好可以提供将这些查表压力卸载到不同的设备中。 |
2、地址翻译过程
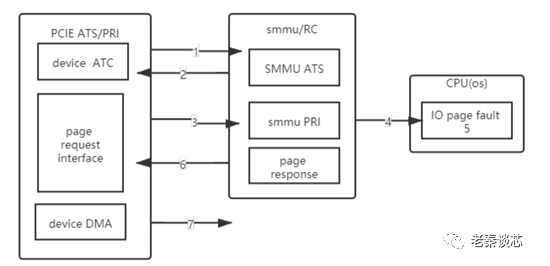
1
2
3
4
5
6
7
1 PCIE Device首先通过本地ATC查找某页地址的转换,未成功则通过ATS发起针对页地址的translation request
2 SMMU收到RC的地址转换请求,查找本地TLB,如果没有,硬件进行page table walk,若页表不存在或者页不在内存中,则需要返回translationfault给PCIE device.
3 PCIE PRI 发起page request给RC,携带streamID,substreamID,地址等信息
4 SMMU获得该信息后组成数据格式包放入PRI queue ,并产生中断通知CPU(OS)
5 OS 内存管理子系统将缺页补上,即处理IO Page fault handling
6 SMMU(RC)通过response告知device,发送page response,页处理完成,该内存页已经准备好,可进行DMA操作
7 PCIE Device发起DMA操作
五、昇腾SMMU和MMU共页表?
PASID is an optional feature that enables sharing of a single Endpoint device across multiple processes while providing each process a complete 64-bit virtual address space. In practice, this feature adds support for a TLP prefix that contains a 20-bit address space that can be added to memory transaction TLPs.
一、由AMD的SVA方案开始
reference:
IOMMU_TUTORIAL_ASPLOS_2016.pdf

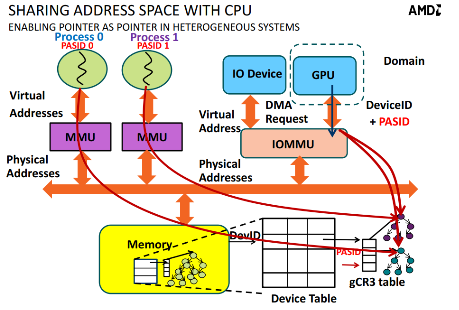
1
2
3
Sharing AMD64 Processor and IOMMU Page Tables—GPA-to-SPA
If software requires 64-bit processor virtual addresses to be identical to I/O virtual addresses, including negative addresses, software needs to configure the IOMMU with the 6-level paging structure illustrated in Figure 13, where 4 extra 4-Kbyte page tables (shaded) at levels 6, 5, and 4 are used solely by the IOMMU, and sharing with processor page tables occurs only at levels 3 and below.
二、推到社区的SVA
reference:Shared Virtual Addressing for the IOMMU
SVA mostly aims at simplifying DMA management.
补丁列表:2017/11/17
https://www.spinics.net/lists/kernel/msg2651481.html
https://www.spinics.net/lists/arm-kernel/msg609771.html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
Sharing process address spaces with devices allows to rely on core kernel
memory management for DMA, removing some complexity from application and
device drivers. After binding to a device, applications can instruct it to
perform DMA on buffers obtained with malloc.
The device, buses and the IOMMU must support the following features:
* Multiple address spaces per device, for example using the PCI PASID
(Process Address Space ID) extension. The IOMMU driver allocates a
PASID and the device uses it in DMA transactions.
* I/O Page Faults (IOPF), for example PCI PRI (Page Request Interface) or
Arm SMMU stall. The core mm handles translation faults from the IOMMU.
* MMU and IOMMU implement compatible page table formats.
This series requires to support all three features. I tried to
facilitate using only a subset of them but enabling it requires more
work. Upcoming patches will enable private PASID management, which
allows device driver to use an API similar to classical DMA,
map()/unmap() on PASIDs. In the future device drivers should also be
able to use SVA without IOPF by pinning all pages, or without PASID by
sharing the single device address space with a process.
Although we don't have any performance measurement at the moment, SVA
will likely be slower than classical DMA since it relies on page faults,
whereas classical DMA pins all pages in memory. SVA mostly aims at
simplifying DMA management, but also improves security by isolating
address spaces in devices.
Intel and AMD IOMMU drivers already offer slightly differing public
functions that bind process address spaces to devices. Because they don't
go through an architecture-agnostic API, only integrated devices could
use them so far.
referecence: Linux SVA特性分析(未完)
这个特性的补丁涉及到IOMMU, PCI, 内存管理(MM),SMMU, VFIO, 虚拟化,DT, ACPI等方面的修改,所以补丁比较分散

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
sva.c
Hardware tables describing this configuration in the IOMMU would typically
* look like this:
*
* PASID tables
* of domain A
* .->+--------+
* / 0 | |-------> io_pgtable
* / +--------+
* Device tables / 1 | |-------> pgd X
* +--------+ / +--------+
* 00:00.0 | A |-' 2 | |--.
* +--------+ +--------+ \
* : : 3 | | \
* +--------+ +--------+ --> pgd Y
* 00:01.0 | B |--. /
* +--------+ \ |
* 00:01.1 | B |----+ PASID tables |
* +--------+ \ of domain B |
* '->+--------+ |
* 0 | |-- | --> io_pgtable
* +--------+ |
* 1 | | |
* +--------+ |
* 2 | |---'
* +--------+
* 3 | |
* +--------+
*
* With this model, a single call binds all devices in a given domain to an
* address space. Other devices in the domain will get the same bond implicitly.
* However, users must issue one bind() for each device, because IOMMUs may
* implement SVA differently. Furthermore, mandating one bind() per device
* allows the driver to perform sanity-checks on device capabilities.
*
* On Arm and AMD IOMMUs, entry 0 of the PASID table can be used to hold
* non-PASID translations. In this case PASID 0 is reserved and entry 0 points
* to the io_pgtable base. On Intel IOMMU, the io_pgtable base would be held in
* the device table and PASID 0 would be available to the allocator.
*/
linux 4.19代码
1
2
3
4
5
6
7
8
9
10
11
12
//sva.c
__iommu_sva_bind_devicestruct device *dev, struct mm_struct *mm, int *pasid, unsigned long flags, void *drvdata
+->io_mm_alloc
+->iommu_ops.mm_alloc //arm_smmu_ops.mm_alloc = arm_smmu_mm_alloc
+->iommu_pasid_table_ops.alloc_shared_entry //
+->arm_smmu_alloc_shared_cd //cd->ttbr = virt_to_phys(mm->pgd); cd保存页表入口
->io_mm_attach
+->arm_smmu_mm_attach
+->ops->set_entry //arm_smmu_set_cd
+->arm_smmu_write_ctx_desc //将mm->pgd刷到对应pasid ttrb中
//至此device n的SMMU页表与进程A的MMU页表已经share,共同使用了
//后面都是通过pagefault调用handle_mm_fault来处理缺页流程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
//sva.c 注册IOMMU page fault evt处理函数
iommu_sva_device_init //iommu_register_device_fault_handler dev iommu_queue_iopf 注册设备的io page fault处理函数
//io-pgfault.c
//处理evt
iommu_queue_iopf
+1-> list_add(fault, group)//等待将group的所有fault evt
2->INIT_WORK(work, iopf_handle_group) //初始化pgfault处理worker
//fault处理worker
iopf_handle_group
->iopf_handle_single for group->faults //对group fault遍历处理
//iopf_handle_single
> evt pgfault request: pasid addr perm权限
1、mm = iommu_sva_find(pasid): evt pgfault request的pasid -> mm
2、vma = find_extend_vma(mm, addr)
3、handle_mm_fault(vma, prm->addr, fault_flags, NULL); //处理page fault
linux 5.10:
1
2
3
4
5
6
7
8
9
//设备绑定进程
iommu_sva_bind_device(struct device *dev, struct mm_struct *mm, void *drvdata)
+->iommu_group_do_bind_dev for group dev
+->intel_iommu_ops.sva_bind //intel_svm_bind
+->intel_svm_bind_mm
+1->intel_iommu_enable_pasid //1.使能pasid
2->ioasid_alloc //申请pasid
3->mmu_notifier_register //注册mmu通知链,处理页表变化支持flush操作
4->intel_pasid_setup_first_level(iommu, dev, pgd, pasid, did, flags) //将进程pgd设置到pasid的第一级页表中
1
2
3
4
5
6
7
//处理pagefault
init_dmars //intel iommu probe
+->intel_svm_enable_prq //CONFIG_INTEL_IOMMU_SVM=y && 支持pasid && 支持 prs page request support
+->thread_create(prq_event_thread) //dmar%d-prq内核线程处理iommu的page fault事件
+->1 ioasid_find(pasid) //从pasid获取svm
->2 find_extend_vma(svm->mm, addr) //从mm和addr获取vma
->3 handle_mm_fault(vma, addr,x, x)//处理pagefault
Extended Capability Register: 《vt-directed-io-spec.pdf 》11.4.3 Extended Capability Register