
一、HMM是什么?
Reference:异构内存管理 Heterogeneous Memory Management (HMM)
翻译于:https://elixir.bootlin.com/linux/v5.5-rc2/source/Documentation/vm/hmm.rst
提供基础设施和帮助程序以将非常规内存(设备内存,如板上 GPU 内存)集成到常规内核路径中,其基石是此类内存的专用结构页面(请参阅本文档的第 5 至 7 节)。
HMM 还为 SVM(共享虚拟内存)提供了可选的帮助程序,即允许设备透明地访问与 CPU 一致的程序地址,这意味着 CPU 上的任何有效指针也是该设备的有效指针。这对于简化高级异构计算的使用变得必不可少,其中 GPU、DSP 或 FPGA 用于代表进程执行各种计算。
本文档分为以下部分:在第一部分中,我揭示了与使用特定于设备的内存分配器相关的问题。在第二部分中,我揭示了许多平台固有的硬件限制。第三部分概述了 HMM 设计。第四部分解释了 CPU 页表镜像的工作原理以及 HMM 在这种情况下的目的。第五部分处理内核中如何表示设备内存。最后,最后一节介绍了一个新的迁移助手,它允许利用设备 DMA 引擎。
1 特定设备内存分配器
设备有大量的板载内存,历来都是专有驱动的API管理,使得驱动程序的内存使用与常规应用内存使用断开,存在分裂。
1、大型程序需要依赖大量的库,使得程序维护复杂
2、复杂数据,例如:复杂数据集(列表、树……),在驱动与应用之间copy的话,由于重复的数据集和地址,这很容易出错并且程序更难调试。
3、由于各种内存副本,大型项目会受到这种影响并浪费资源。
复制每个库 API 以接受由每个设备特定分配器分配的输入或输出内存不是一个可行的选择。这将导致库入口点的组合爆炸。
随着高级语言结构(在 C++ 中,但在其他语言中)的进步,编译器现在可以在没有程序员知识的情况下利用 GPU 和其他设备。某些编译器识别的模式仅适用于共享地址空间。对所有其他模式使用共享地址空间也更合理。
2 IO总线与设备内存特性
io总线的访问存在缓存一致性问题,以及访问带宽问题。虽然已经有新的协议加入PCIE中,希望来解决前面问题。但并不是所有都支持。
为了使共享地址空间有意义,我们不仅必须允许设备访问任何内存,而且还必须允许任何内存在设备使用时迁移到设备内存(在发生时阻止 CPU 访问)。
3 共享地址空间及迁移
Hmm提供两个功能:
1、统一虚拟地址空间:通过复制设备页表中的 CPU 页表来共享地址空间,因此对于进程地址空间中的任何有效主内存地址,相同的地址指向相同的物理内存;
2、ZONE_DEVICE 内存:它允许为设备内存的每个页面分配一个结构页面,管理设备内存。
4 地址空间镜像实现
1、页表同步:mmu_interval_notifier_insert
2、设备驱动程序想要填充一个虚拟地址范围:hmm_range_fault
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
int driver_populate_range(...)
{
struct hmm_range range;
...
range.notifier = &interval_sub;
range.start = ...;
range.end = ...;
range.hmm_pfns = ...;
if (!mmget_not_zero(interval_sub->notifier.mm))
return -EFAULT;
again:
range.notifier_seq = mmu_interval_read_begin(&interval_sub);
mmap_read_lock(mm);
ret = hmm_range_fault(&range);
if (ret) {
mmap_read_unlock(mm);
if (ret == -EBUSY)
goto again;
return ret;
}
mmap_read_unlock(mm);
take_lock(driver->update);
if (mmu_interval_read_retry(&ni, range.notifier_seq) {
release_lock(driver->update);
goto again;
}
/* Use pfns array content to update device page table,
* under the update lock */
release_lock(driver->update);
return 0;
}
5 内存迁移
由于 CPU 无法直接访问设备内存,因此设备驱动程序必须使用硬件 DMA 或设备特定的加载/存储指令来迁移数据。migrate_vma_setup()、migrate_vma_pages() 和 migrate_vma_finalize() 函数旨在使驱动程序更易于编写并集中跨驱动程序的通用代码。
6 内存记账
目前,设备内存被视为 rss 计数器中的任何常规页面(如果设备页面用于匿名,则为匿名,如果设备页面用于文件支持页面,则为文件,如果设备页面用于共享内存,则为 shmem)。这是为了保持现有应用程序的故意选择,这些应用程序可能在不知情的情况下开始使用设备内存,运行不受影响。
一个缺点是 OOM 杀手可能会杀死使用大量设备内存而不是大量常规系统内存的应用程序,因此不会释放太多系统内存。在决定以不同方式计算设备内存之前,我们希望收集更多关于应用程序和系统在存在设备内存的情况下在内存压力下如何反应的真实世界经验。
对内存 cgroup 做出了相同的决定。设备内存页面根据相同的内存 cgroup 计算,常规页面将被计算在内。这确实简化了进出设备内存的迁移。这也意味着从设备内存迁移回常规内存不会失败,因为它会超过内存 cgroup 限制。一旦我们对设备内存的使用方式及其对内存资源控制的影响有了更多的了解,我们可能会在后面重新考虑这个选择。
二、深入
https://www.kernel.org/doc/html/latest/vm/hmm.html
1
2
https://www.jianshu.com/p/7e2f9b8d59ca
HMM的讨论从社团的一个问题开始:像GPU这样的设备需要哪些功能以便能够支持HMM? 答案是,它需要某种页表结构,可用于设置每页内存的访问权限。 例如,这取决于在相关页面中找到哪种类型的代码,设置权限使得其可以执行在CPU或GPU上(但不是在两者上)。 HMM还需要能够防止两个处理器的同时写入,因此GPU需要能够处理故障(handle faults)。
1 硬件功能
(1)像GPU这样的设备需要哪些功能以便能够支持HMM? 一致的设备内存节点CDM coherent device memory nodes?1
http://www.voidcn.com/article/p-gtgnskkx-bad.html
异构内存管理(HMM)让设备的驱动程序可以为受制于自身内存管理的进程来镜像地址空间。正如Red Hat的开发人员杰尔姆·格利瑟(Jérôme Glisse)解释(https://lkml.org/lkml/2017/4/21/872),这项功能让GPU之类的硬件设备更容易直接访问进程的内存,没有复制任何内容所带来的额外开销。它也并不侵犯现代操作系统所提供的内存保护功能。
势必会从HMM获得最大好处的一类应用就是基于GPU的机器学习。诸如OpenCL和CUDA之类的机器学习库的速度到时有望得到HMM的提升。HMM做到这点的方式与针对基于GPU的机器学习进行的提速几乎一模一样,也就是说让数据留在原地、靠近GPU,在那里直接处理数据,然后传输尽可能少的数据。
让HMM适用于Linux中面临几个障碍。首先是内核支持,而在相当长的时间里,内核对HMM的支持一直情况不明朗。早在2014年,HMM最初是作为Linux内核补丁集(patchset)提出来的,Red Hat和英伟达都是关键开发商。涉及的工作量并不小,但是开发人员认为,可以提交代码,说不定可以加入到未来发布的几个内核版本。
第二个障碍是视频驱动程序支持,英伟达一致在单独搞这项工作。据格利瑟声称,AMD GPU可能也会支持HMM,所以这种特别的优化不会仅限于英伟达GPU。AMD一直在提升其在GPU市场的实力,因此可能会在同一块晶片上整合GPU处理和CPU处理(http://www.infoworld.com/article/3099204/hardware/amd-mulls-a-cpugpu-super-chip-in-a-server-reboot.html)。然而,软件生态系统仍然明显青睐英伟达;将来需要另外几个像HMM这样与厂商中立的项目,以及与CUDA所提供的性能不相上下的OpenCL性能,才可能获得切实的选择。
第三个障碍是硬件支持,因为HMM需要有一种可再现的页面故障(replayable page faults)硬件功能才能发挥作用。目前只有英伟达的Pascal高端GPU系列支持这项功能。从某种意义上来说,这是好消息,因为它意味着英伟达只需要为某一个硬件提供驱动程序支持――它需要完成的工作量较小,就可以让HMM正常使用起来。
一旦HMM实施到位,使用GPU实例的公共云提供商将面临压力:需要支持最新最好一代的GPU。不是仅仅把老式的英伟达Kepler显卡换成最先进的Pascal GPU就完事。由于后续的每一代GPU会显得更脱颖而出,像HMM这样的支持优化将带来战略优势。
2 replayable page faults
(2)硬件支持:replayable page faults硬件功能是什么?1
https://on-demand.gputechconf.com/gtc/2017/presentation/s7764_john-hubbardgpus-using-hmm-blur-the-lines-between-cpu-and-gpu.pdf
3 How HMM works?
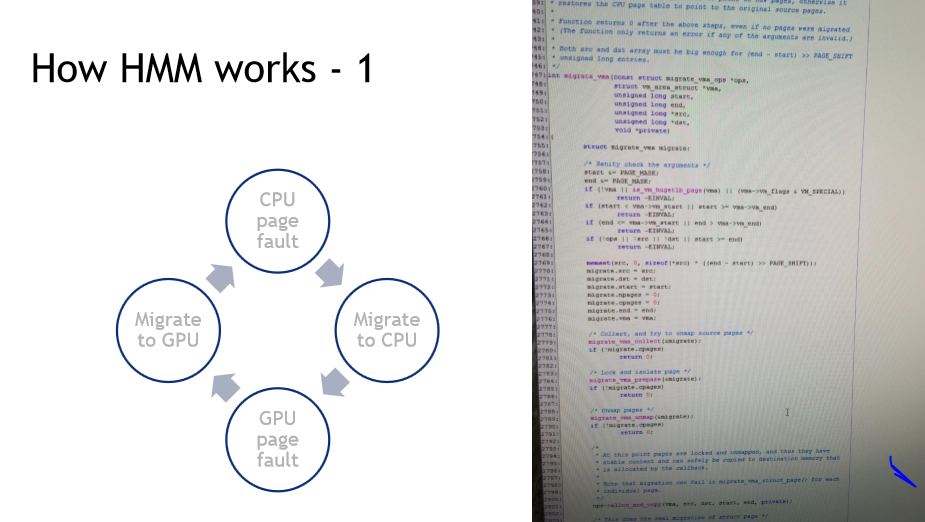

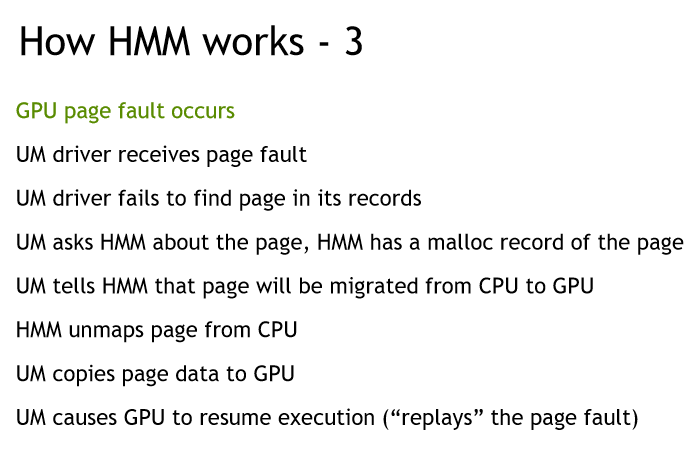
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
https://nvidia.github.io/open-gpu-doc/manuals/turing/tu104/dev_mmu_fault.ref.txt
2 - GPU FAULT BUFFER
======================================
This chapter describes the format of the GPU replayable and
non-replayable fault reporting buffer used to report page faults.
This fault buffer is written to by GMMU based on buffer location info
set in GMMU registers (NV_PFB_PRI_MMU_REPLAY_FAULT_BUFFER_LO/HI and
NV_PFB_PRI_MMU_NON_REPLAY_FAULT_BUFFER_LO/HI). The replayable fault
buffer is managed by the UVM driver. The non-replayable fault buffer
is managed by RM.
The buffer can overflow. There is status maintained in GMMU register
for that. If the buffer has overflowed the GPU will stop writing out new fault
entries and proceed to drop entries until SW resets the overflow
status (normally after processing the existing fault packets and so
GET PTR is changed). This is done to prevent the GPU from overwriting
unprocessed entries. When faults are dropped they are not lost for
replayable faults as the requets are buffered in MMU replay buffer;
however, non-replayable faults are lost as those requests are not
buffered for further processing; when SW triggers a replay event the
requests for the dropped replayable faults will be replayed, fault
again, and then be reported in the fault buffer.
缓冲区可能溢出。GMMU寄存器中保存了这种状态。如果缓冲区溢出,GPU将停止写入新的故障条目,并继续丢弃条目,直到SW重置溢出状态(通常在处理现有的故障数据包之后,因此GET PTR被更改)。这样做是为了防止GPU覆盖未处理的条目。当故障丢弃时,它们不会因为可重放的错误而丢失,因为请求被缓存在MMU重放缓冲区中;但是,由于这些请求没有缓存以便进一步处理,非重放的错误会丢失;当SW触发重放事件时,对丢弃的可重放故障的请求将被重放,再次发生故障,然后在故障缓冲区中报告。
replayable page faults
1
https://smartech.gatech.edu/bitstream/handle/1853/62741/KIM-DISSERTATION-2020.pdf
1
https://www.redhat.com/files/summit/session-assets/2017/S104078-hubbard.pdf




三 疑问
(1)driver如何收到GPU运行的pagefault? 为什么gpu会产生page faults? GPU有单独的MMU?
GPU page fault:
1
2
3
https://winddoing.github.io/post/793.html
GPU 页错误
A GPU page fault commonly occurs under one of these conditions. An application mistakenly executes work on the GPU that references a deleted object. This is one of the top reasons for an unexpected device removal. An application mistakenly executes work on the GPU that accesses an evicted resource, or a non-resident tile.
GPU 页面错误通常在下列情况之一下发生: 1) 应用程序在 GPU 上错误地执行了应用已删除的对象的作业。 这是意外删除设备的主要原因之一。 2) 应用程序错误地在 GPU 上执行了访问已逐出的资源或非驻留磁贴的作业。 3) 着色器引用未初始化的或过时的描述符。 4) 着色器索引超出根绑定末尾。
1
2
3
4
```c
https://www.zhihu.com/question/381126048
链接:https://www.zhihu.com/question/381126048/answer/1093535046
现在的CPU,是通过将需要GPU执行的命令写入内存(主存),然后通知GPU命令开始的地址与长度,来与GPU协作的。GPU可见的内存一般分为两部分:和CPU共享的(一般为主存的一部分),以及独占的(一般为显存)。GPU执行的程序以及相关参数(如顶点坐标),一般放在共享的内存里面,因为这些是需要CPU不断更新的。 GPU绘图所需资源(如贴图),由CPU从外存(如硬盘)读入之后,先临时放在共享内存上,然后通知GPU将其转移到GPU专有内存(显存)当中。现代GPU在绘图命令之外,一般还至少有一个专门的用来转移数据的命令队列,可以和绘图命令队列并行执行。GPU的执行结果(绘制的画面)一般直接写入显存当中的特定区域(屏幕缓冲区),然后由专门的ScanOut电路(包括在GPU当中或者显卡上)对其完成最终的数字信号处理之后(如色空间转换,Gamma调整等)输出给显示设备。因此,如果CPU想要读取GPU计算的结果,需要通知GPU将结果传输回共享内存区域,这通常有较大的性能开销。
1
2
http://www.irisa.fr/alf/downloads/ADA/Tanasic_ExceptionGPUs_Micro17.pdf
Ecient Exception Handling Support for GPUs
GPU有独立的MMU。
(2)CPU如何识别是设备内存的page fault?
中断通知driver, 处理faults.
四、总结支持HMM的要求
(1)设备支持handles faults能力,支持类似MMU页表能力
通过CPU和device的页表设置来保证设备和CPU只有一个在访问虚拟地址
(2)设备支持replay faults的;
驱动一般通过中断通知driver处理faults, driver需要存储replayed fault(page faults),driver处理完fault后需要replay触发faults的语句。
五、HMM VS DSM
1 HMM
(1)设备支持handles faults能力,支持类似MMU页表能力
(2)设备支持replay faults的
2 DSM
(1) 由于线程共享相同的虚拟地址空间,因此所有线程必须具有相同的内存视图。
3 HMM VS DSM
| 前置条件 | 优势 | |
|---|---|---|
| HMM | (1) 支持handles faults,支持类似MMU页表能力,可以设置not present含义 (2) 支持handles faults之后replay fault的方法。 |
|
| DSM | (1) 所有va都是相同的内存视图 Main memory需要预留和device memory完全镜像的内存。 要支持相同的地址翻译硬件设备。 (2) page coherency机制需要消息通知或者监控手段。 |
1、数据没有发生写,不需要同步,可以直接访问。 |