
一、HCCS
Cache一致性总线HCCS,可以实现CPU和CPU之间的高速互联,通信速率高达每秒30GT,是业界主流CPU互联速率的2倍多。
1
2
3
4
通过多CPU互联,我们率先实现256个物理核的NUMA架构,从而推出业界首款兼容ARM架构的最强算力4路服务器。
异构计算的兴起,使得CPU与NPU之间的互联协议也很关键。华为创新性的将HCCS同样应用于CPU与NPU的高速互联
,构建了xPU间的统一Cache一致性架构,xPU之间可以进行直接内存访问,实现高速数据交互。同时基于此架构,
可实现通用算力和AI算力的灵活组合,打造最强算力的异构计算服务器。
二、HBM HIGH Bandwidth memory
1
2
https://china.xilinx.com/support/documentation/white_papers/c_wp485-hbm.pdf
硅与硅的堆叠结构允许通过非常小、分布非常密集的微凸块来连接相邻的硅器件
三、CXL
1
https://zhuanlan.zhihu.com/p/65435956
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
https://www.techdesignforums.com/practice/technique/compute-express-link-cxl-protocols/
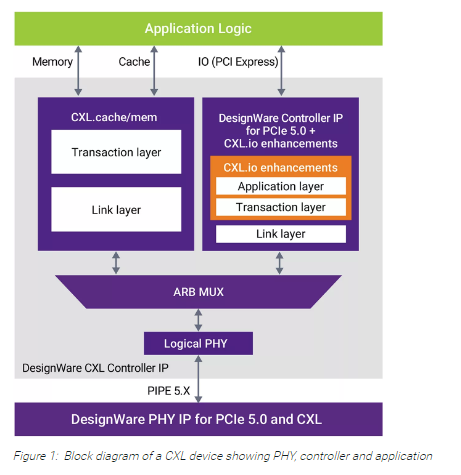
The CXL standard defines three protocols that are dynamically multiplexed together before
being transported via a standard PCIe 5.0 PHY at 32GT/s.
The CXL.io protocol is an enhanced version of a PCIe 5.0 protocol that can be used for
initialization, link-up, device discovery and enumeration, and register access. It
provides a non-coherent load/store interface for I/O devices.
The CXL.cache protocol defines interactions between a host and a device, allowing attached
CXL devices to efficiently cache host memory with extremely low latency using a request and
response approach.
The CXL.mem protocol provides a host processor with access to the memory of an attached
device using load and store commands, with the host CPU acting as a master and the CXL
device acting as a subordinate. This approach can support both volatile and persistent memory architectures.
1
https://www.synopsys.com/designware-ip/technical-bulletin/compute-express-link-standard-2019q3.html