
一、 简介
Intel不仅是最大的CPU公司,还是全球最大的软件公司之一,10万员工中有1.5万都是软件工程师。在OS系统上,Intel也开发了多种系统了,现在最新产品是mOS,一款专用于HPC超算的高性能Linux变种。Intel的mOS系统很少人关注,官方透露的细节也不多,目前还在开发中,主要用于高性能计算,在超算负载中可以提供更好的并行性及可靠性。
mOS系统依然会基于Linux扩展而来,目前最新版0.8版使用的是Linux 5.4 LTS内核,但它又有自己的LWK轻量级内核,Linux内核管理少量部分CPU核心,以确保兼容性,LWK内核管理系统其他部分,类似Mutil-OS多OS。
Intel的mOS已经在ASCI Red,IBM Blue Gene等超算上应用,不过它最终的目标是用于2021年的百亿亿次超算Aurora上,后者采用了未来一代的Intel至强可扩展处理器、Intel Xe计算架构、Intel未来一代的傲腾DC可持续内存、Intel One API软件等。
该超算同时采用Cray的新一代超算平台“Shasta”,由超过200个机柜组成,支持Cray Slingshot高性能可扩展互连架构,并在软件堆栈方面针对Intel架构进行专门优化。
二、mOS内存管理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
1:什么是Mos
Mos是一款intel 开发的,针对HPC场景优化的os,目前已经开源,其开源网址为https://github.com/intel/mOS。
2:Mos和linux kernel的区别。
Mos 是在linux kernel的根目录下面加了一个mos的文件夹,里面放的是Mos的主要文件,总结一下,Mos就是内嵌到linux kernel中的一个轻量级os.
3: Mos 的工作原理
通过命令行参数 lwkcpus 和lwkmem 来隔离内存和cpu,或则通过lwkctl 来在linux kernel启动后来隔离cpu和内存。
其中lwkcpus的使用举例如下
lwkcpus=<syscall cpu1>.<lwkcpu set1>:<syscall cpu2>.<lwkcpu set2>...
For example:
lwkcpus=28.1-13,29-41:42.15-27,43-55
https://github.com/intel/mOS/wiki/mOS-for-HPC-v0.8-Administrator's-Guide
The following parameters and values are recommended for mOS for HPC. Not all combinations and variations of boot parameters have been validated and tested. Boot failure is possible if, for example, lwkcpus and lwkmem are not properly set for your system. The lwkcpus and lwkmem parameters can be omitted and the lightweight kernel partition created after booting using the lwkctl command. Please refer to Documentation/kernel-parameters.txt in the mOS for HPC kernel source for further details.
4:应用怎么运行到Mos上
正常不加任何前缀的话,应用运行在linux kernel上,加yod的话,应用运行在Mos中
https://github.com/intel/mOS/wiki/mOS-for-HPC-v0.8-User's-Guide
The yod utility of mOS is the fundamental mechanism for spawning LWK processes. The syntax is:
yod yod-arguments program program-arguments
5:linux kernel 和Mos的关系
————————————————
版权声明:本文为CSDN博主「tiantao2012」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/tiantao2012/article/details/113852469
1
lwkcpu=8.9-15 lwkmem=0:128G,1:128G
1
2
lwk_config_lwkmem //入参为NULL,destroy mem;反之create.
->if param_value == NULL ? lwkmem_partition_destroy : lwkmem_partition_create
1、lwkmem_partition_create创建lwkmem partition
1
2
3
4
5
6
7
8
9
10
11
12
#define __ATTR_RW(_name) __ATTR(_name, 0644, _name##_show, _name##_store)
static struct kobj_attribute lwk_config_attr = __ATTR_RW(lwk_config);
->lwk_config_store lwk_config_show
///strcmp(s_keyword, "lwkmem")
lwk_config_store
->lwk_config_lwkmem
//系统启动
rest_init
->kernel_init //在free_initmem之后
->lwkctl_def_partition
->lwk_config_lwkmem
1
2
3
lwkmem_partition_create
->lwkmem_parse_args //spec参数,解析mos_lwkmem_nodes, mos_lwkmem_size信息.
->mos_mem_init
1)mos_mem_init初始化内存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
mos_mem_init
->for_each_node_mask allocate_memory_from_linux(nid, req_size)
//申请的nid上内存记录在static struct lwkmem_designated lwkmem[MAX_NUMNODES];中
/*
* lwkmem[MAX_NUMNODES],
* Used to track all the physical memory ranges designated to LWK.
* An element at index N gives the lwkmem_designated structure that
* embeds the list head for all designated memory granules and
* keeps the counters that indicate number of free and available
* memory in terms of pages on that NUMA node.
*
* lwkmem[NID] lwkmem_granule lwkmem_granule
* +--------------+ +-----------------+ +-----------------+
* | list |----->| list_designated |--->| list_designated |
* | n_resv_pages | | list_reserved | | list_reserved |
* | n_free_pages | | base | | base |
* +--------------+ | length | | length |
* | owner | | owner |
* +-----------------+ +-----------------+
*/
1
2
3
4
5
6
7
8
9
10
11
12
13
//mOS/lwkmem/pma_buddy.c
static struct lwk_pm_factory_operations pma_buddy_factory_ops = {
.alloc_pma = alloc_pma_buddy,
.free_pma = free_pma_buddy
};
static struct lwk_pm_operations pma_buddy_ops = {
.alloc_pages = buddy_alloc_pages,
.free_pages = buddy_free_pages,
.split_page = buddy_split_page,
.report = buddy_report,
.meminfo = buddy_meminfo,
.setup = buddy_setup
};
1
2
3
//注册pma操作,申请、释放、拆分、报告、统计、setup
pma_buddy_init
->register_lwk_pma //pm_registered_ops
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
lwkmem_early_init
->mos_register_process_callbacks //mos_process_callbacks
//lwkmem_callbacks回调来执行lwkmem_process_start申请lwkmem
static struct mos_process_callbacks_t lwkmem_callbacks = {
.mos_process_init = lwkmem_process_init,
.mos_process_start = lwkmem_process_start,
.mos_process_exit = lwkmem_process_exit,
};
lwkmem_process_start
->start_lwk_mm
->| curr_lwk_mm
->| lwk_mm_set_mempolicy_info
->| [Assigning Values] //lwk_mm->pma = pma_buddy_factory_ops->alloc_pma; lwk_mm->pm_ops = pma_buddy_ops
->| pma_buddy_ops->setup
1
2
3
4
5
6
7
MOS_SYSFS_CPU_WO(lwkcpus_request);
static struct mos_sysfs_mask_write_op name##_mask_op = { \
.parser = cpumask_parse, \
.operation = _##name##_set, \ ///here
};
_lwkcpus_request_set
->mos_get_process //给进程设置mos_process current->mos_process
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
static struct kobj_attribute lwkmem_request_attr = __ATTR_WO(lwkmem_request);
lwkmem_request_store
->lwkmem_request
->allocate_lwk_mm //lwk_mm->vm_ops = &lwk_vm_ops;
->set_lwk_mm //设置给进程
//mOS/lwkmem/mm.c
static struct lwk_vm_operations lwk_vm_ops = {
.get_unmapped_area = lwk_mm_get_unmapped_area,
.unmap_page_range = lwk_mm_unmap_pages,
.move_page_tables = lwk_mm_move_page_tables,
.change_protection = lwk_mm_change_protection,
.follow_page = lwk_mm_follow_page,
.page_fault = lwk_mm_page_fault,
.alloc_pages_vma = lwk_mm_alloc_pages_vma,
.vma_adjust = lwk_mm_vma_adjust,
.populated = lwk_mm_vma_populated,
.fork = lwk_mm_fork,
.clear_heap = lwk_mm_clear_heap,
.elf_map = lwk_mm_elf_map,
};
//include/linux/moslwkmem.h
#define lwkmem_get_unmapped_area_ops() \
curr_lwk_mm()->vm_ops->get_unmapped_area
#define lwkmem_page_fault(vma, addr, flags)\
vma_lwk_mm(vma)->vm_ops->page_fault(vma, addr, flags)
#define lwkmem_unmap_range(vma, start, end)\
vma_lwk_mm(vma)->vm_ops->unmap_page_range(vma, start, end)
#define lwkmem_change_protection_range(vma, start, end, prot) \
vma_lwk_mm(vma)->vm_ops->change_protection(vma, start, end, \
prot)
#define lwkmem_vma_adjust(vma, start, end) \
vma_lwk_mm(vma)->vm_ops->vma_adjust(vma, start, end)
#define lwkmem_follow_page(vma, addr, flags, pagemask) \
vma_lwk_mm(vma)->vm_ops->follow_page(vma, addr, flags, pagemask)
#define lwkmem_move_page_tables(old_vma, old_addr, new_vma, new_addr, len) \
vma_lwk_mm(old_vma)->vm_ops->move_page_tables(old_vma, \
old_addr, new_vma, new_addr,\
len)
#define lwkmem_populated(vma) \
vma_lwk_mm(vma)->vm_ops->populated(vma)
#define lwkmem_fork(oldvma, newvma) \
vma_lwk_mm(oldvma)->vm_ops->fork(oldvma, newvma)
#define lwkmem_clear_heap(vma, oldbrk, newbrk) \
vma_lwk_mm(vma)->vm_ops->clear_heap(vma, oldbrk, newbrk)
#define lwkmem_elf_map(s, len, fp, off, addr, sz, tsz) \
curr_lwk_mm()->vm_ops->elf_map(s, len, fp, off, addr, sz, tsz)
2、lwkmem_partition_destroy销毁lwkmem partition
三、how use? yod
问题2: syscall cpu1/utility_cpus 怎么使用,处理syscall 什么意思?
1
2
3
4
syscall 指令:
https://man7.org/linux/man-pages/man2/syscall.2.html
syscall调用流程:
http://gityuan.com/2016/05/21/syscall/
1
2
3
4
//mOS/mos.c
yod -> 调用sysfs接口
_lwkcpus_request_set
cpumask_or(current->mos_process->utilcpus, current->mos_process->utilcpus, utility_cpus_map); //utilcpus
1
2
3
4
5
6
7
8
9
10
11
12
copy_process:2087
这个写的也太详细了: http://gityuan.com/2017/08/05/linux-process-fork/
sched_fork -> .task_fork
//.task_fork = task_fork_mos,
// Called on fork with the child task as argument from the parent's context
//- child not yet on the tasklist
//- preemption disabled
task_fork_mos
->|push_utility_threads
->||select_linux_utility_cpus //选择utility_cpus的CPU
->||push_to_linux_scheduler //push到linux调度域?
->|set_utility_cpus_allowed
问题3: lwkcpu的调度是个简化版,具体原理?
1
2
http://www.wowotech.net/process_management/447.html //调度类实现
https://linuxtoy.org/archives/bfs-intro-future-of-linux-desktop-kernel.html 脑残调度器
1
2
3
4
5
6
7
8
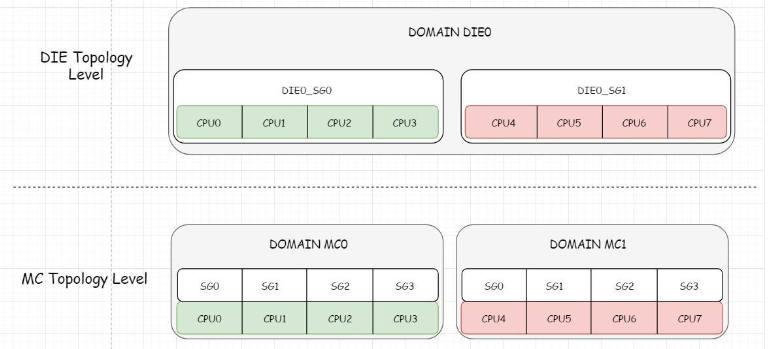
CPU拓扑结构存在下面三个level(SMT level最低):
SMT Level 超线程处理器的一个核心
MC Level 多核CPU的一个核心
DIE Level 一个物理CPU的晶片(注意不是package,package是封装好了的,肉眼看到的CPU处理器)
cpu最小级别的就是超线程处理器的一个smt核,次小的一级就是一个多核cpu的核,然后就是一个物理cpu封装,再往后就是cpu阵列,根据这些cpu级别的不同,Linux将所有同一级别的cpu归为一个“调度组”,然后将同一级别的所有的调度组组成一个“调度域”cpu最小级别的就是超线程处理器的一个smt核,次小的一级就是一个多核cpu的核,然后就是一个物理cpu封装,再往后就是cpu阵列,根据这些cpu级别的不同,Linux将所有同一级别的cpu归为一个“调度组”,然后将同一级别的所有的调度组组成一个“调度域”
对于ARM 架构,目前由于不支持超线程技术,只有DIE和MC两个Topology Level
————————————————
原文链接:https://blog.csdn.net/wukongmingjing/article/details/81664820 调度域和调度组
16 * kernel/sched/mos.c
17 *
18 * When executing on a CPU that has been designated to be an LWK CPU, all tasks
19 * are managed by the mOS scheduler. However, the tasks within the mOS
20 * scheduler must occasionally interact with the Linux scheduler. For
21 * example, a Linux/mOS task may be blocked on a mutex held by a mOS/Linux task
22 * and will need to be awakened when the resource is released. Also when an
23 * mOS process is executing on an Linux core due to evanescence, this task must
24 * obey the rules of the linux scheduler. This file contains the mOS scheduler
25 * and the mos scheduler class that allow the the two schedulers to
26 * interoperate.
在指定为LWK CPU的CPU上执行时,所有任务都由mOS调度程序管理。但是,mOS调度程序中的任务偶
尔必须与Linux调度程序交互。例如,Linux/mOS任务可能会在mOS/Linux任务持有的互斥体上被阻
止,并且需要在释放资源时唤醒。此外,当mOS进程因消失而在Linux核心上执行时,此任务必须遵
守linux调度程序的规则。此文件包含允许两个调度程序互操作的mOS调度程序和mos调度程序类。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
const struct sched_class mos_sched_class
__attribute__((section("__mos_sched_class"))) = {
.enqueue_task = enqueue_task_mos,
.dequeue_task = dequeue_task_mos,
.yield_task = yield_task_mos,
.check_preempt_curr = check_preempt_curr_mos,
.pick_next_task = pick_next_task_mos,
.put_prev_task = put_prev_task_mos,
#ifdef CONFIG_SMP
.balance = balance_mos,
.select_task_rq = select_task_rq_mos,
.set_cpus_allowed = set_cpus_allowed_mos,
.rq_online = rq_online_mos,
.rq_offline = rq_offline_mos,
.task_woken = task_woken_mos,
.switched_from = switched_from_mos,
#endif
.set_next_task = set_next_task_mos,
.task_tick = task_tick_mos,
.get_rr_interval = get_rr_interval_mos,
.prio_changed = prio_changed_mos,
.switched_to = switched_to_mos,
.update_curr = update_curr_mos,
.task_fork = task_fork_mos,
};
抓个lwkcpu的调度轨迹?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
static struct mos_process_callbacks_t lwksched_callbacks = {
.mos_process_init = lwksched_process_init,
.mos_process_start = lwksched_process_start,
.mos_thread_exit = lwksched_thread_exit,
.mos_process_exit = lwksched_process_exit,
};
lwksched_mod_init
->|mos_register_process_callbacks lwksched_callbacks
static struct mos_process_callbacks_t lwkmem_callbacks = {
.mos_process_init = lwkmem_process_init,
.mos_process_start = lwkmem_process_start,
.mos_process_exit = lwkmem_process_exit,
};
subsys_initcall lwkmem_early_init
->mos_register_process_callbacks lwkmem_callbacks
定论1:lwkcpu只能一个program使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//mOS/tools/yod/mos_plugin.c
struct yod_plugin mos_plugin = {
.get_designated_lwkcpus = mos_get_designated_lwkcpus,
.get_reserved_lwk_cpus = mos_get_reserved_lwk_cpus,
.request_lwk_cpus = mos_request_lwk_cpus,
.set_util_threads = mos_set_util_threads,
.map_cpu = mos_map_cpu,
.get_designated_lwkmem = mos_get_designated_lwkmem,
.get_reserved_lwkmem = mos_get_reserved_lwkmem,
.request_lwk_memory = mos_request_lwk_memory,
.get_numa_nodes_online = mos_get_numa_nodes_online,
.lock = mos_combo_lock,
.unlock = mos_combo_unlock,
.get_distance_map = mos_get_distance_map,
.lwkcpus_sequence_request = mos_lwkcpus_sequence_request,
.set_options = mos_set_options,
.set_lwkmem_mempolicy_info = mos_set_lwkmem_mempolicy_info,
.get_mos_view = mos_get_mos_view,
.set_mos_view = mos_set_mos_view,
.get_lwk_processes = mos_get_lwk_processes,
};
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
//kernel/fork.c
//都是通过调用execvp直接继承设置的属性, 先通过提供的sys接口设置current task_struct里面的mos_process使用lwkcpu和lwkmem。lwk_mm_fork.
dup_mmap
->lwkmem_fork
->lwk_mm_fork
//CLONE_THREAD 继承父进程的mos_process.
static __latent_entropy struct task_struct *copy_process(...
{
...
2199: #ifdef CONFIG_MOS_FOR_HPC
if (clone_flags & CLONE_THREAD) {
/* A copy of an LWK thread is also an LWK thread. */
p->mos_flags = current->mos_flags;
p->mos_process = current->mos_process;
if (current->mos_process)
atomic_inc(¤t->mos_process->alive);
} else {
/* A copy of an LWK process is not an LWK process. */
p->mos_flags = current->mos_flags & ~MOS_IS_LWK_PROCESS;
p->mos_process = NULL;
/* All Linux processes inherit the mOS view from its parent.
* The child process can override its view later by writing to
* its /proc/self/mos_view or by some other process writing to
* /proc/<pid>/mos_view
*
* This rule is not applicable to LWK processes. The child
* process starts off with the default view and does not in-
* -herit view from its parent LWK process.
*
* No need to lock child process since it is not yet active.
*/
if (is_mostask())
SET_MOS_VIEW(p, MOS_VIEW_DEFAULT);
}
#endif
...
}
1
//mOS/tools/yod/yod.c
四、lwkmem内存管理数据结构
五、MPI 跨域通信
1
2
3
4
https://www.codenong.com/10542284/
Open MPI功能的方式是将其分为多个层,并且每个层的功能由动态加载的多个模块提供。有一种计分机制可以在特定条件下选择最佳模块。
所有MPI实现都提供一种进行所谓SPMD启动的机制。本质上,MPI应用程序是SPMD(单程序多数据)的一种特殊类型-运行单个可执行文件的多个副本,并将消息传递用作通信和协调的机制。 SPMD启动器获取执行节点列表,远程启动流程并在它们之间建立关联和通信方案(在Open MPI中,这称为MPI Universe)。它是创建全局MPI通信器MPI_COMM_WORLD并分配初始等级分配的一种,它可以提供诸如将进程绑定到CPU内核的选项(在NUMA系统上非常重要)。一旦启动了进程,则可以使用某种识别机制(例如,等级与IP地址/ TCP端口之间的映射),可以采用其他寻址方案。例如,开放式MPI使用ssh,rsh启动远程进程,也可以使用其他资源管理系统提供的机制(例如PBS / Torque,SLURM,Grid Engine,LSF ...)。一旦进程启动并且它们的IP地址和端口号在Universe中记录和广播,进程就可以在其他(更快)网络上找到彼此,例如InfiniBand,并在它们之间建立通信路由。
路由消息通常不是由MPI自己完成的,而是留给底层的通信网络。 MPI仅负责构造消息,然后将它们传递到网络以传递到目的地。对于驻留在同一节点上的进程之间的通信,通常使用共享内存。
问题一: HPC应用的特点? 通信的主要用途是什么? 关乎内存管理算法?
问题二:等待队列?lwk域是否能使用?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
openMPI mpirun四个线程:
Thread 1是主线程,在启动业务进程运行后,调用poll等待业务进程运行结束。业务进程结束后,Thread 1完成清理工作退出。
Thread 2是progress thread,负责进程之间的异步通信,提供非阻塞的通信功能。线程启动后,会调用epoll_wait等待事件的到来。
Thread 3是本地连接监听线程,负责建立本地连接。线程启动后,调用select等待事件。
Thread 4是tcp监听线程,负责建立tcp连接。线程启动后,调用select等待事件。
mpirun运行的后台线程是mpi进程间通信必不可少的,它们都有一个共同的特点,就是大部分时间都处于阻塞状态,没有在运行。这和lwk相性不佳,lwk上运行的线程是资源独占(CPU + 内存)的,直到退出才会释放资源,如果mpirun的后台线程在lwk上运行,会造成计算资源的浪费。
另外对于进程间的通信,同步通信在lwk域内就可以完成,但是异步通信需要跨域进行(需要和progress thread交互),从这点来看,“跨域”确实可能会对通信造成一定的影响。
HPCG:高性能共轭梯度计算,超算性能的标准测试套。主要涉及 计算、访存、进程通信,一般要达到高性能,都需要针对CPU架构进行专门的优化,包括数据结构,代码流程,甚至是指令级别的优化。
intel针对自己的CPU架构做了MPI + hpcg的优化,如果要在intel的CPU上达到高性能,需要使用intel oneapi + intel hpcg。
目前来看,lwk和MPI进程通信的相性不是很好:在lwk上运行的线程,可能会被MPI进程通信阻塞,而当前线程占用的CPU资源是无法让给其他线程运行的,这就会造成CPU资源的浪费。
这个问题有两个思路,一是使用MPI_Isend类似的接口,这是MPI提供的非阻塞调用,但是需要修改程序,兼容性很差;二是正面从架构上解决这个问题,目前mOS这种隔离运行的方式太过死板了(但应该是为了性能考虑),CPU资源其实是进程独占,而不是简单的lwk域独占,一旦进程被I/O阻塞,进程占有的整个CPU资源就都被浪费掉了。
1
2
3
4
5
6
7
8
9
10
crc计算卸载到计算域?
那这个cpu预留就削减整体的性能了?
如何快速的动态隔离出域?
2个CPU处理一个ready队列, 2个核进行抢锁,
https://cloud.tencent.com/developer/article/1517909 MuqSS调度器 有意思!!
2个cpu绑在一起,来并行两个调度类。
cpu active状态设置为其他状态,隔离起来?
1) 局部的最优解
2) 减小load balance的锁粒度